
Are your data engineering and data science teams working in silos? Do you want your teams to not only share data within your Lakehouse platform but also to align on core principles and ways of working?
A cultural shift
Data Engineering and Business Intelligence have traditionally been structured and methodical, with BI offering stability but lacking speed and flexibility. Data Science is more iterative, exploratory, and flexible — it is faster, but potentially less controlled. Data Science is more iterative, exploratory, and flexible — it is faster, but potentially less controlled.
The Databricks Intelligence Platform enables seamless collaboration between data engineers and data scientists by providing shared tools and functionalities for different personas and project types.
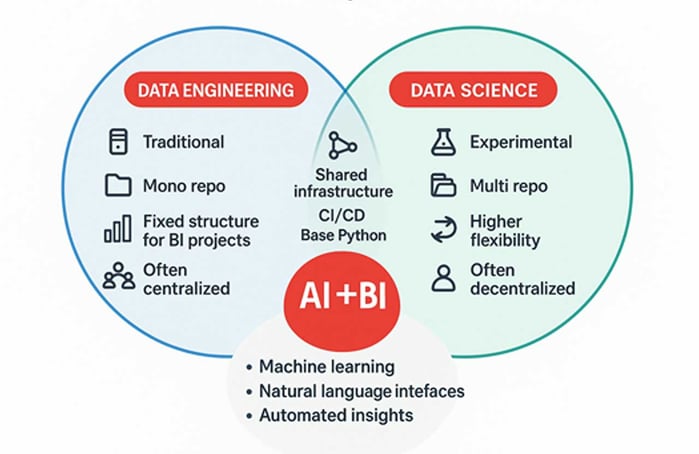
Several new terms and trends are emerging that reflect the fusion of machine learning, natural language interfaces, and automated insights in traditional BI tools.
Closer collaboration between Data Engineering and Data Science is more than just a cultural shift — it directly impacts the efficiency, quality, and scalability of data-driven work.
Streamline project setup with Databricks Custom Assets Bundles Templates
In this article, I’ll demonstrate an efficient way to deploy a streamlined project structure, tailored to different engineering or data science needs.
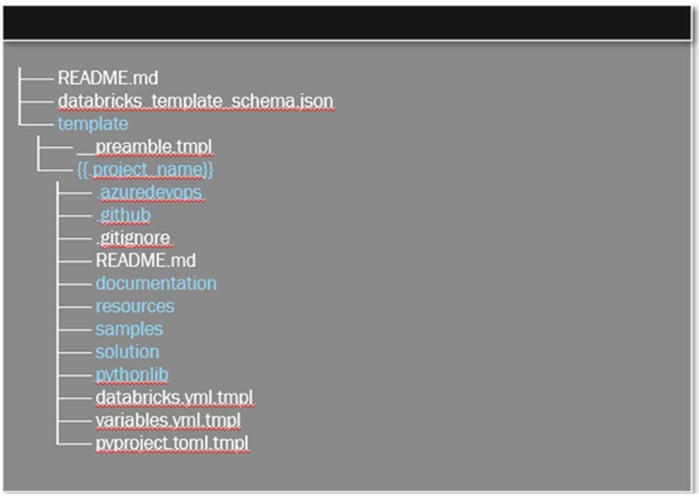
We’ve developed a Databricks Asset Bundle custom template that includes best practices for both worlds (engineering, data science), featuring the following elements with the chosen project type:
- Project structure
- Sample notebooks
- Base Python modules
- Deployment pipelines
- Unity Catalog resources
- Cost and quality monitors
To set up a project, you can now use the Databricks CLI to initialize a bundle.
You’ll be prompted to enter a project name and select from various options defined in the template. Within seconds, a fully customized project is created. By using the same template across teams, your colleagues will create consistent and recognizable project structures — enhancing reusability, streamlining collaboration, and establishing a solid foundation for shared development practices.

DABS Templates are repeatable bundles
If a Databricks asset bundle defines the deployable content of a project, templates are reusable bundles with customizable parameters and components.
The databricks.yaml file in a DAB supports Go templating, a lightweight and powerful templating system originally from the Go programming language.
What Go Templating Enables:
- Conditional logic: Use , blocks to include or exclude resources based on project-specific values. For example, only include ML models or notebooks if the project type is "data science".
- Reusable variables: Define variables like project_name, env, or resource_path once and inject them throughout the configuration file. This keeps things easy to maintain.
- Parameter-driven templates: Prompt users to input parameters (like project type, language, or cloud provider) and dynamically generate the appropriate structure and resources.
Example Use Cases:
- Automatically name jobs, clusters, or folders using a project_name variable.
- Include additional folders like /ml/ or /pipelines/ only if the project is ML-related.
- Configure environments (dev, staging, prod) using a single template by toggling values with blocks.
The simplicity of Assets Bundle Templates is its actual strength.
Check it out here: https://learn.microsoft.com/en-us/azure/databricks/dev-tools/bundles/templates